
본 포스트는 부스트캠프에서 진행한 벽전 프로젝트의 서버 성능을 개선해보고자 진행한 내용을 정리한 포스트입니다.
들어가며
부하 테스트 툴로는 nGrinder를 사용하였고, 진행 방식은 다음과 같다.
- 대상 API - 메인 페이지의 랜덤 전시회 조회 API
- Vuser - 1000명
에러 개선기
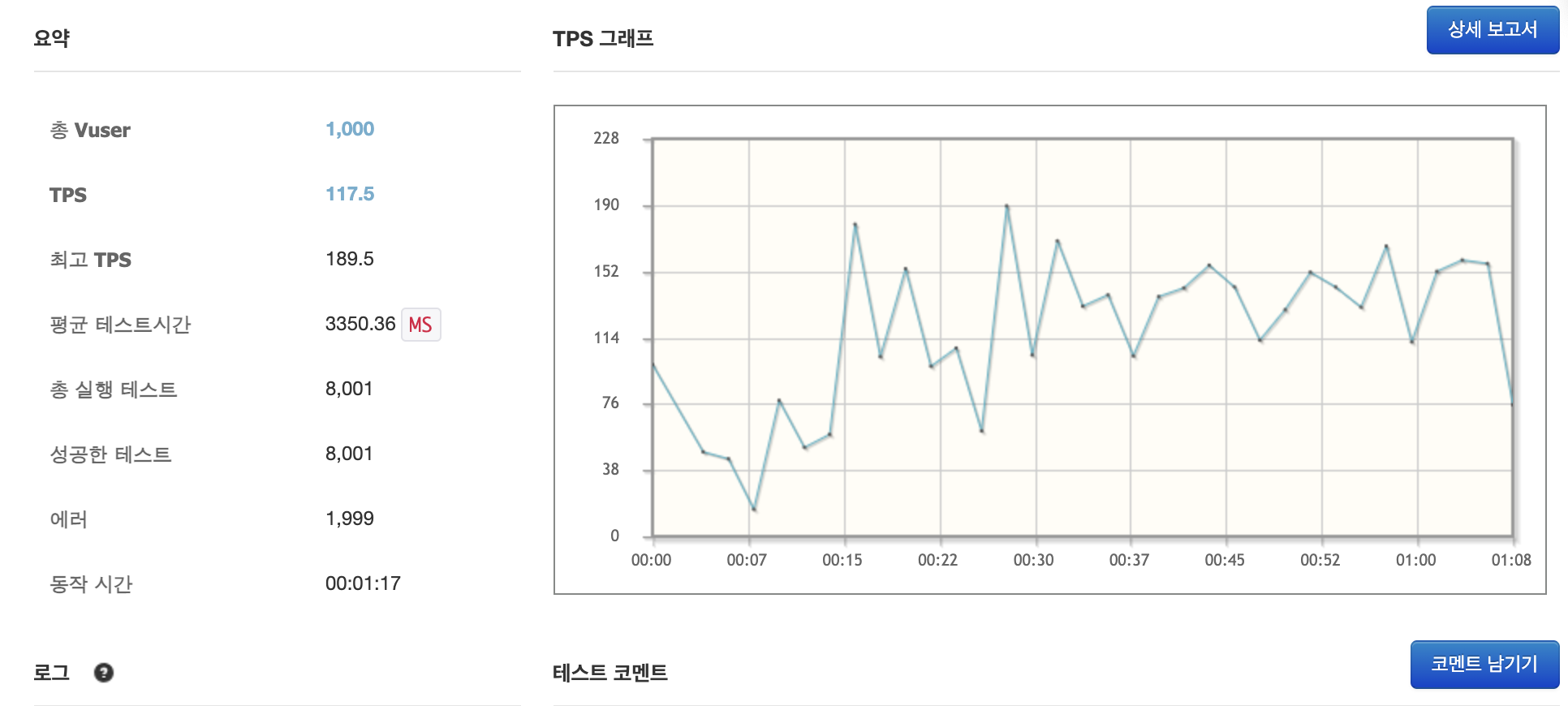
부하 테스트를 진행해보았더니 여러 에러가 발생하여 정확한 성능 측정을 할 수 없었다. 따라서 성능 개선을 하기 전에 우선적으로 발생한 에러들에 대해 다루어보려고 한다.
Error: worker_connections are not enough
처음으로 발생한 에러는 worker_connections are not enough 였다. 해당 에러는 Nginx의 worker connection이 부족하여 1000명의 가상 유저를 감당하지 못하여 발생한 것이며, 실제 Nginx의 default worker connections를 확인해보았더니 512개임을 확인할 수 있었다.
해당 문제를 해결하기 위해서 Nginx 설정 파일에서 worker_connections의 값을 2048로 설정해주었고, 더 이상 connection에 대한 에러가 발생하지 않았다.
Error: Too many open files

하지만 connection의 개수가 충분하니 Too many open files 라는 에러가 곧바로 발생하였다.
해당 에러는 발생하는 이유는 소켓이 열릴 때마다 하나의 파일로 분류되는데, 프로세스가 연 파일의 개수가 Linux의 프로세스 당 열 수 있는 파일의 최대 개수를 넘어버려 발생하는 것이다.
etc/security/limits.conf
#<type> can have the two values:
# - "soft" for enforcing the soft limits
# - "hard" for enforcing hard limits
#<item> can be one of the following:
# - nofile - max number of open files
* soft nofile 4096
* hard nofile 4096etc/nginx/nginx.conf
worker_rlimit_nofile 4096;이러한 에러는 Linux 시스템의 open files와 Nginx의 worker_rlimit_nofile 값을 설정하여 프로세스 당 열 수 있는 파일의 최대 개수를 늘려줌으로써 해결할 수 있다.
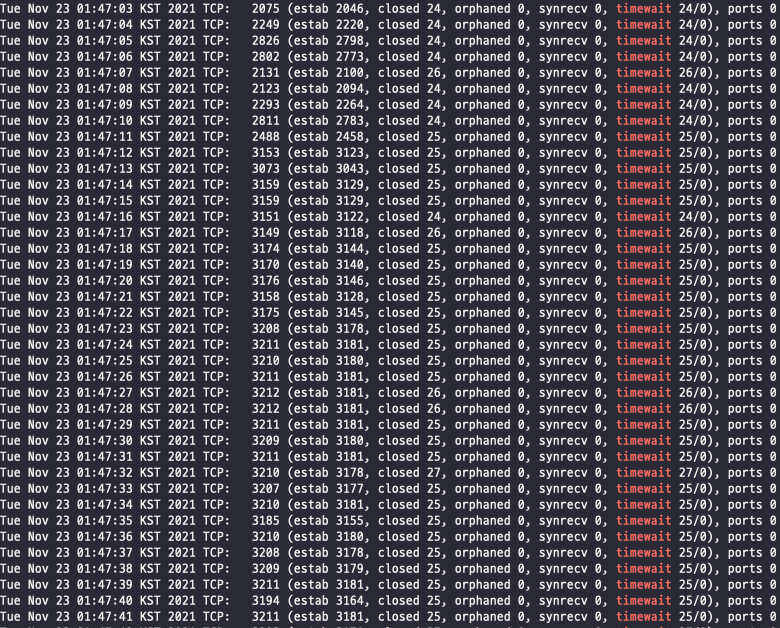
Time_wait 소켓 증가

Nginx worker가 서버에 요청을 전달해줄 때 Nginx에서 소켓을 만들게 되는데, 하나의 요청이 끝난 소켓이 연결을 끊기 위해 진행되는 TCP의 4-way handshake 과정 중 time_wait 상태에 들어서게 되면서 소켓이 쌓이는 문제가 발생하였다.
해당 에러를 해결하기 위해 고민하던 중 Nginx와 서버 간에 연결된 세션을 재사용하면 어떨까? 라는 생각이 들었다.
Nginx와 서버 간에 연결된 세션을 재사용한다면 TCP 연결이 종료되는 과정에서 소켓이 쌓이는 문제도 해결할 수 있을 뿐만 아니라, 매 요청마다 3-way handshake를 통해 세션을 구축하는 비용도 줄일 수 있을 것 같다는 생각을 하였다.
이와 같은 생각을 반영할 수 있는 방법으로는 Nginx의 keepalive 설정이 있다.
etc/nginx/sites-available/server.conf
upstream backend {
server 127.0.0.1:3001;
keepalive 1024;
}
...해당 설정을 진행한 뒤, 다시 한 번 부하 테스트를 진행해보면 time_wait 소켓의 개수가 많이 줄어드는 것을 확인할 수 있다.
성능 개선
서버의 성능을 개선하기 위해 부하 테스트를 진행해보았는데, 위와 같이 많은 에러가 발생하여 시도조차 하지 못하였다. 부하 테스트를 진행하며 발생하는 에러들을 해결해보았으니, 이제 성능 개선을 진행해보도록 하자.
성능 개선을 진행할 API는 메인 페이지에 접속할 때 호출되는 랜덤 전시회 조회 API로, 해당 API는 랜덤한 전시회 5개와 각 전시회의 작품들을 조회해오는 기능을 가지고 있다.
기존 코드 부하 테스트
랜덤 전시회 조회 API는 5개의 전시회 조회 쿼리 + 각 전시회에 속한 작품들을 조회해오는 쿼리 = 총 6번의 쿼리가 발생하는 API이다.
- 전시회 서비스 계층
async getRandomExhibitions(): Promise<ExhibitionDTO[]> {
const exhibitions = await this.exhibitionRepository.findRandomExhibitions();
return Promise.all(
exhibitions.map(async exhibition => {
const artworks = await this.artworkRepository.findAllByExhibitionId(exhibition.id);
return ExhibitionDTO.from(exhibition, artworks);
}),
);
}- 전시회 레포지토리 계층
async getRandomExhibitions(): Promise<Exhibition[]> {
return await this.createQueryBuilder('exhibition')
.innerJoinAndSelect('exhibition.artist', 'artist')
.orderBy('RAND()')
.limit(5)
.getMany();
}- 작품 레포지토리 계층
async findAllByExhibitionId(exhibitonId: number, relations?: string[]): Promise<Artwork[]> {
return await this.find({
where: { exhibitionId: exhibitonId },
relations: relations,
});
}- nGrinder 부하 테스트 결과

위 nGrinder의 부하 테스트 결과를 보면 TPS(Throughput Per Second)가 208로 측정된 것을 알 수 있고, 이제 이 TPS를 향상시켜보도록 하자.
첫 번째 시도: 인덱스의 사용
기존 테이블의 구조는 다음과 같이 작품 테이블에서 전시회 테이블의 기본 키를 갖고 있던 구조였다.
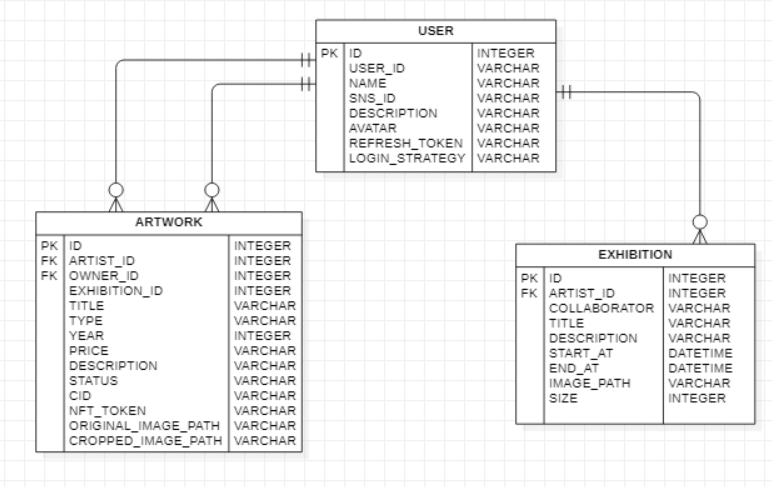
위 구조와 기존 코드에서는 랜덤한 5개의 전시회를 조회해온 뒤, 각 전시회 엔티티를 순회하며 전시회에 속한 작품들을 조회해오는 로직으로 구성되어 있었다.
즉, 랜덤한 5개의 전시회 조회 쿼리 1번 + 전시회에 포함된 작품 조회 쿼리 5번이 발생하게 된다.
이러한 구조와 코드에서 개선할 수 있는 부분을 고민해보다가, 작품의 PK를 활용하여 인덱스를 타도록 만들면 어떨까? 라는 생각을 하였다. 그리고 이 의견을 적용해보면서 변경한 테이블 구조는 다음과 같다.

작품 테이블에서 작품이 속한 전시회의 기본 키를 갖는 것이 아니라, 전시회 테이블에서 전시회에 속한 작품들의 기본 키를 갖도록 하는 것이다.
그리고 이러한 작품들의 기본 키를 활용하도록 개선한 코드는 다음과 같다.
- 전시회 서비스 계층
async getRandomExhibitions(): Promise<ExhibitionDTO[]> {
const exhibitions = await this.exhibitionRepository.findRandomExhibitions();
return Promise.all(
exhibitions.map(async exhibition => {
const artworks = await this.artworkRepository.findAllByArtworkIds(JSON.parse(exhibition.artworkIds));
return ExhibitionDTO.from(exhibition, artworks);
}),
);
}- 작품 레포지토리 계층
async findAllByArtworkIds(artworkIds: number[], relations?: string[]): Promise<Artwork[]> {
return await this.find({
where: { id: In(artworkIds) },
relations: relations,
});
}위 코드에서 랜덤한 전시회 5개를 조회해온 뒤, 각 전시회에 포함된 작품들은 작품의 PK로 조회하는 것을 알 수 있다.
즉, 작품 테이블의 Primary Index를 사용해보았고, 그 결과 다음과 같이 성능을 향상시킬 수 있었다.
- TPS 208에서 244.6으로 증가

두 번째 시도: Join의 제거
랜덤 전시회 조회 API와 클라이언트에서 사용하는 전시회 정보를 분석해보던 중 전시회 정보에서 작가의 정보는 이름만을 사용한다는 것을 알게 되었다. 그리고 이는 곧 반정규화를 통해 조인을 제거해보는 것은 어떨까? 하는 생각으로 이어졌다.
물론 작가가 이름을 변경할 가능성을 감안한다면 연관관계를 두는 것이 맞다. 하지만 작가의 이름을 변경하는 쿼리보다 메인 페이지에서 전시회를 조회하는 쿼리가 훨씬 더 많이 발생하기 때문에 반정규화를 적용해볼 만한 가치가 있다고 판단하였다.
따라서 다음과 같이 사용자와 전시회 테이블 간의 연관관계를 제거해주었고, 전시회 테이블에 전시회를 개최한 작가명 필드를 추가해주었다.
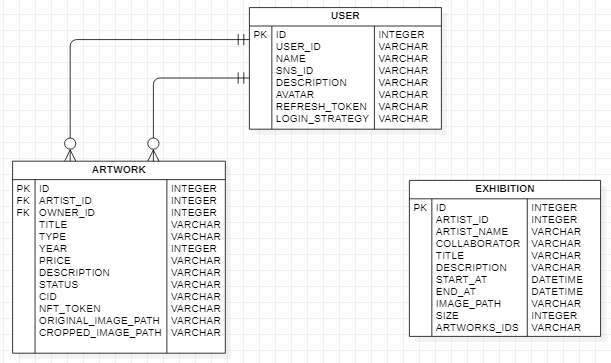
그리고 이에 맞게 엔티티를 수정하고, 레포지토리 계층의 로직을 다음과 같이 수정해주었다.
- 전시회 레포지토리 계층
async findRandomExhibitions(): Promise<Exhibition[]> {
return await this.createQueryBuilder('exhibition')
// .innerJoinAndSelect('exhibition.artist', 'artist') user와의 연관관계를 없앴다.
.orderBy('RAND()')
.limit(5)
.getMany();
}이후 부하 테스트를 다시 진행해보았고, 그 결과 다음과 같이 성능을 향상시킬 수 있었다.
- TPS 244.6에서 253.5로 증가
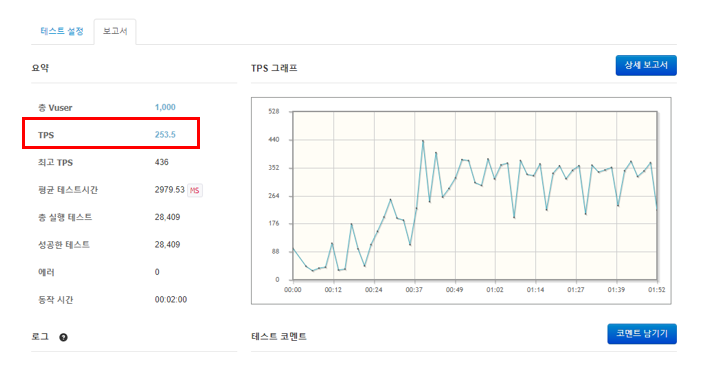
세 번째 시도: 작품 조회 쿼리 개수 개선
기존에는 Promise.all을 통해 앞서 조회한 랜덤 전시회 5개만큼의 작품 조회 쿼리가 발생하였다.
이 5번의 쿼리가 발생하는 부분을 개선해보고 싶었고, 고민 끝에 한 번에 랜덤 전시회 5개에 포함된 모든 작품을 조회해온 뒤 애플리케이션 레벨에서 파싱을 해주면 어떨까? 라는 생각을 하였다.
- 전시회 서비스 계층
// 개선 이전 - SELECT 쿼리 6개
async getRandomExhibitions(): Promise<ExhibitionDTO[]> {
const exhibitions = await this.exhibitionRepository.findRandomExhibitions(); // 1번
return Promise.all(
exhibitions.map(async exhibition => {
const artworks = await this.artworkRepository.findAllByArtworkIds(JSON.parse(exhibition.artworkIds)); // 5번
return ExhibitionDTO.from(exhibition, artworks);
}),
);
}
// 개선 이후 - SELECT 쿼리 2개
async getRandomExhibitions(): Promise<ExhibitionDTO[]> {
const exhibitions = await this.exhibitionRepository.getRandomExhibitions(); // 1번
const artworkIds = exhibitions.reduce((prev, exhibition) => [...prev, ...JSON.parse(exhibition.artworkIds)], []);
const artworks = await this.artworkRepository.findAllByArtworkIds(artworkIds); // 1번
return exhibitions.map(exhibition => {
const isSale = JSON.parse(exhibition.artworkIds).some((artworkId) => {
const found = artworks.find(artwork => artwork.id === Number(artworkId));
return found.status === ArtworkStatus.InBid;
});
return ExhibitionDTO.from(exhibition, isSale);
});
}위와 같이 기존 작품 조회 단계에서 5번의 쿼리가 발생하던 로직을 1번의 쿼리만 발생하도록 개선해보았다.
즉, 수정 전에는 랜덤 전시회 조회 1번 + 전시회 당 포함된 작품 조회 5번 = 총 6번의 쿼리 발생에서
수정 후에는 랜덤 전시회 조회 1번 + 전시회들에 포함된 모든 작품 조회 1번 = 총 2번의 쿼리 발생으로 줄어든 것이다.
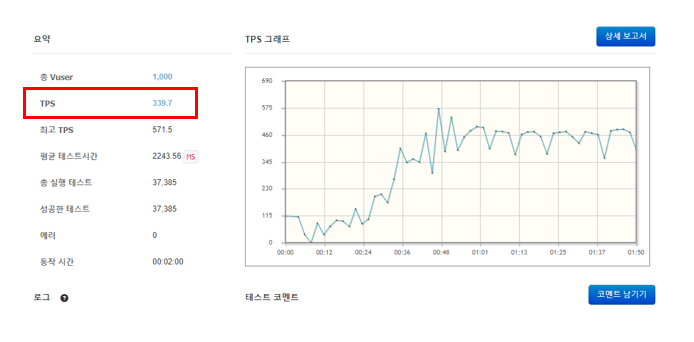
이 로직을 가지고 부하 테스트를 다시 진행해보았고, 그 결과 한 단계 더 개선된 결과를 볼 수 있었다.
- TPS 253.5에서 339.7로 증가
마치며
부하 테스트를 처음 진행해보았는데, 흥미로운 이슈들을 많이 만날 수 있어서 재밌었다. 하지만 부하 테스트 동작 시간에 대한 설정 미흡과 APM 툴을 같이 도입하여 분석해보았다면 더 좋지 않았을까? 등등에 대한 아쉬움이 남는 것 같다.
이번 경험을 바탕으로 더 학습해서 다음 성능 개선 때는 더 재밌게 공부할 수 있도록 노력해야 겠다는 생각이 든다.
혹시 잘못된 부분이 있다면 지적 혹은 조언 부탁드립니다:)