
들어가며
프로젝트를 진행하던 도중 의도와는 다른 개수의 엔티티가 조회되는 흔히 "데이터 뻥튀기"라고 불리는 문제가 발생하였다.
해당 문제가 무엇이고, 왜 발생하는지, 그리고 어떻게 해결할 수 있는지에 대해 알아보도록 하자.
일단 문제가 발생한 엔티티 간의 연관관계를 간단히 나타내보면 다음과 같다.

모든 연관관계가 1 : N 이라는 것을 알 수 있다. 여기서 하나의 Task가 여러 개의 Comment를 가질 수 있다는 점을 주목하고 넘어가도록 하자.
그러면 이제 문제의 상황을 만들어보도록 하겠다.
엔티티 구현
먼저 데이터 뻥튀기 문제에서 사용할 엔티티는 다음과 같다.
// User.java
@Getter
@NoArgsConstructor
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "manager", fetch = FetchType.LAZY)
private List<Task> tasks = new ArrayList<>();
@OneToMany(mappedBy = "writer", fetch = FetchType.LAZY)
private List<Comment> comments = new ArrayList<>();
public User(String name) {
this.name = name;
}
}// Task.java
@Getter
@NoArgsConstructor
@Entity
public class Task {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private String description;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User manager;
@OneToMany(
mappedBy = "task",
fetch = FetchType.LAZY,
cascade = CascadeType.PERSIST,
orphanRemoval = true
)
private List<Comment> comments = new ArrayList<>();
@Builder
public Task(String title, String description, User manager) {
this.title = title;
this.description = description;
this.manager = manager;
}
public void addComment(Comment comment) {
this.comments.add(comment);
}
}// Comment.java
@Getter
@NoArgsConstructor
@Entity
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String contents;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User writer;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "task_id")
private Task task;
@Builder
public Comment(String contents, Task task, User writer) {
this.contents = contents;
this.task = task;
this.writer = writer;
}
}
데이터 뻥튀기 문제 유발
이제 앞서 구현한 엔티티를 가지고, 데이터 뻥튀기 문제가 발생하는 상황을 만들어보도록 하자.
@ActiveProfiles("test")
@DataJpaTest
public class JPADataPoppingTest {
@Autowired
private UserRepository userRepository;
@Autowired
private TaskRepository taskRepository;
@Autowired
private CommentRepository commentRepository;
@BeforeEach
void setUp() {
// 사용자 등록
User user = userRepository.save(new User("yeongkee"));
// 태스크 및 댓글 등록
for (int i = 1; i <= 10; i++) {
Task task = Task.builder()
.title("task title" + i)
.description("task description" + i)
.manager(user)
.build();
Comment firstComment = Comment.builder()
.contents("first comment contents")
.task(task)
.writer(user)
.build();
Comment secondComment = Comment.builder()
.contents("second comment contents")
.task(task)
.writer(user)
.build();
task.addComment(firstComment);
task.addComment(secondComment);
taskRepository.save(task);
}
}
@Test
void 태스크를_댓글과_함께_조회한다() {
List<Task> tasks = taskRepository.findAllTasksWithComments();
assertThat(tasks.size()).isEqualTo(10);
}
}public interface TaskRepository extends JpaRepository<Task, Long> {
// Task를 조회할 때 Task와 관련된 댓글들을 함께 조회해오는 JPQL
@Query("select t from Task t join fetch t.comments")
List<Task> findAllTasksWithComments();
}위 테스트 코드를 살펴보자면, 먼저 @DataJpaTest 어노테이션을 통해 JPA와 관련된 자원들만 가져오도록 하였다.
그 후, @BeforeEach로 설정된 setUp() 메소드에서 1. User를 등록하고, 2. 하나의 Task 당 2개의 Comment를 갖도록 설정하고 등록해주었다.
그리고 이러한 fixture들을 바탕으로 아래 "태스크를_댓글과_함께_조회한다" 테스트에서 태스크의 개수가 의도한 바와 일치하는지 확인해주었다.
이 테스트를 돌려보기 전에 몇 개의 태스크가 나올지 생각해보면 10개의 태스크를 등록했으니 10개가 나오는 것이 의도한 바일 것이다. 하지만 실제로 테스트 코드를 돌려보면 아래와 같이 10개가 아닌 20개가 나오는 것을 확인할 수 있다.
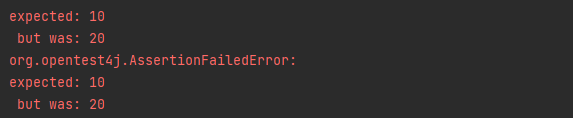
이러한 문제를 흔히 "데이터 뻥튀기" 문제라고 부르는데, 이 문제가 왜 발생하는지 알아보도록 하자.
데이터 뻥튀기 문제 발생
데이터 뻥튀기 문제는 객체와 관계형 데이터베이스 간의 패러다임 불일치로 인해 발생하는 문제이다.
먼저, 앞서 실행한 JPQL을 관계형 데이터베이스 관점에서 표현하면 아래와 같다.
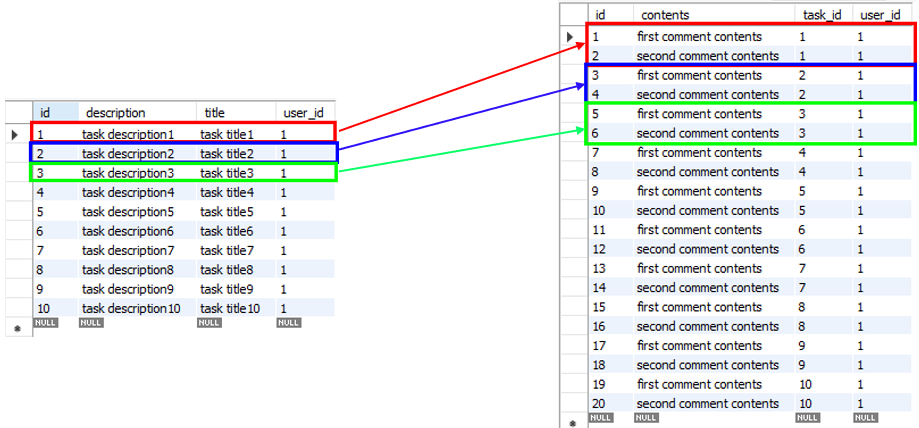
Comment 테이블에 있는 task_id 외래 키를 통해 Task 테이블과 Comment 테이블 간에 조인을 수행할 수 있게 되고, 조인을 수행하면 아래와 같은 결과 테이블이 만들어진다.
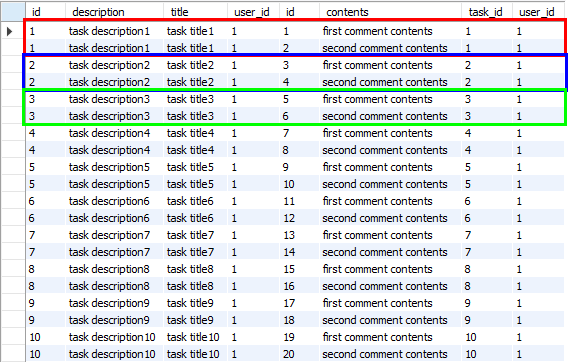
하나의 Task에 두 개의 Comment가 등록되어 있기 때문에 조인 결과를 보면 동일한 Task 레코드를 가진 레코드가 2개씩 존재한다는 것을 알 수 있다.
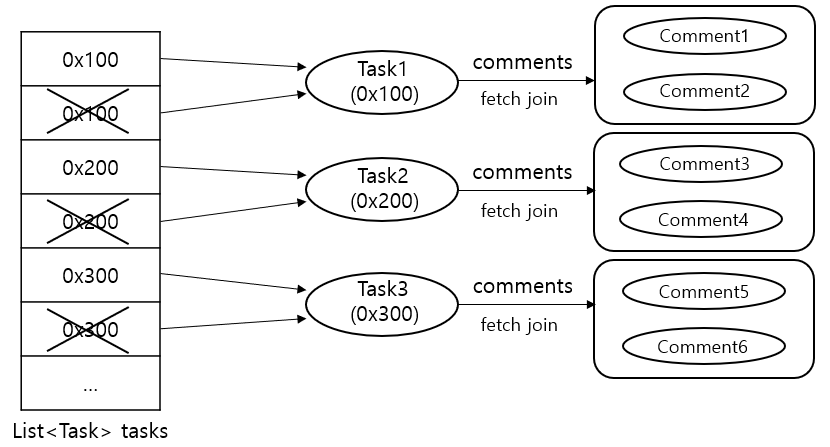
그리고 이러한 데이터베이스 조인의 결과를 객체 관점에 반영하면 아래와 같다.
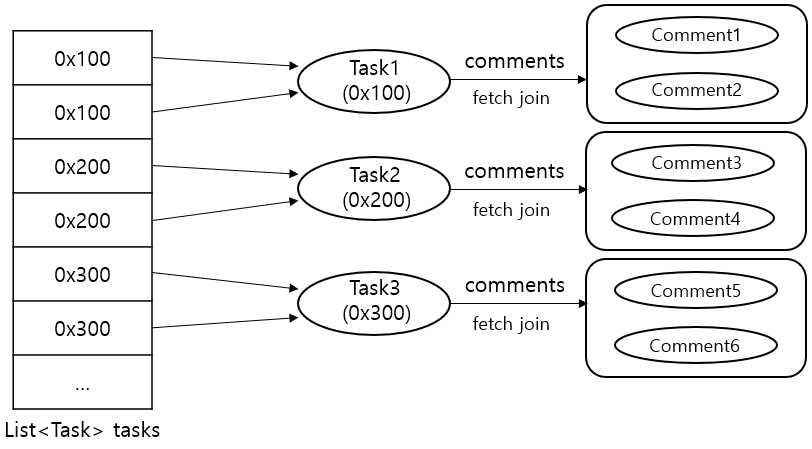
위 그림은 JPA를 통해 Task를 조회하면서 fetch join을 이용해서 연관된 댓글 컬렉션도 함께 조회한 결과로, 각 Task 당 동일한 객체를 2개씩 가지고있다는 것을 알 수 있다.
이러한 결과로 인해 앞서 수행해본 테스트 코드에서 의도한 바보다 2배 더 많은 객체들이 조회된 것이다.
데이터 뻥튀기 문제 발생 원인
JPA는 데이터베이스의 조인 결과를 가져와서 영속성 컨텍스트에 테이블의 기본 키와 매핑한 id 값으로 구분해서 객체를 만들어준다. 하지만 fetch join JPQL의 결과를 반환할 때는 조인된 레코드 개수만큼의 객체를 List에 담아서 반환한다.
예를 들어, "Fig 4. 관계형 데이터베이스 관점의 조인 결과" 그림과 같은 조인 결과가 나온다면 영속성 컨텍스트에는 id값을 기반으로 Task 객체를 하나씩만 생성하지만, 실제 반환할 때는 중복을 신경쓰지 않고 조인 결과 레코드마다 하나의 객체로 반환한다는 것이다.
이로 인해 앞선 예제에서 10개의 Task가 아닌 20개의 Task로 뻥튀기된 것이다.
데이터 뻥튀기 문제 해결 방법
이러한 데이터 뻥튀기 문제를 해결하는 방법으로는 크게 Set을 이용하는 방법과 DISTINCT를 이용하는 방법 2가지가 있다. 두 가지 방법 모두 아래 그림과 같이 엔티티의 중복을 제거해줌으로써 데이터 뻥튀기 문제를 해결한다.
Set 이용하기
Set을 이용하는 방법은 1 : N 연관관계에서 자료형을 Set으로 설정하는 것이다. 이번 예제에서는 Task 엔티티의 comments 를 Set으로 바꾸어주면 된다.
@Getter
@NoArgsConstructor
@Entity
public class Task {
...
@OneToMany(
mappedBy = "task",
fetch = FetchType.LAZY,
cascade = CascadeType.PERSIST,
orphanRemoval = true
)
private Set<Comment> comments = new HashSet<>();
...
}단, Set을 사용할 때는 객체 간의 동등성 비교를 위해 Comment 엔티티에 식별자인 id 필드를 가지고 equals() 와 hashCode()를 오버라이딩 해주어야 한다.
DISTINCT 이용하기
DISTINCT를 이용하는 방법은 아래와 같이 JPQL에 DISTINCT를 추가해주는 것이다.
public interface TaskRepository extends JpaRepository<Task, Long> {
@Query("select distinct t from Task t join fetch t.comments")
List<Task> findAllTasksWithComments();
}JPQL의 DISTINCT 명령어는 SQL에 DISTINCT를 추가해주고, 애플리케이션에서 한 번 더 중복을 제거해주는 기능을 한다.
이를 통해 Task 엔티티의 중복을 제거할 수 있고, JPQL의 결과를 반환받는 List에는 중복된 데이터 없이 의도한 데이터 개수만큼만 들어갈 수 있게 된다.
마치며
데이터 뻥튀기 문제는 1 : N 연관관계 중 1(일)에 해당하는 엔티티에서 N(다)에 해당하는 엔티티를 fetch join할 때 발생하며, 조회되는 데이터의 개수가 의도했던 개수보다 많아지는 문제이다. 이러한 데이터 뻥튀기 문제는 N(다)에 해당하는 엔티티의 레코드가 많으면 많아질수록 뻥튀기되는 크기가 커지기 때문에 유의해야 하는 문제점이고, 데이터 뻥튀기 문제가 발생하는 1(일) -> N(다) fetch join은 꽤나 많이 작성되는 쿼리이기 때문에 내부적으로 어떻게 동작하는지 잘 알고 있어야 한다.